Performance Testing AI is Different: Cost, Tooling and Metrics
With AI applications growing in use, complexity and performance requirements, I would like to share some thoughts that go beyond general load testing, which we’ve already covered in our other posts.

Using AI-generated images in an article about AI is almost mandatory, right?
Cost
Since AI is more compute-heavy than a lot of traditional tasks, load testing them requires a bit more thought. To save on cost, you can apply the regular tricks, like scaling down your test environment to some fraction of your production environment, but if you’re using Agentic AI, there are also some specific tricks to lower costs:
Bypassing the LLM
Testing a web site/service is typically done either on the protocol level (HTTP or WebSocket) or browser level (e.g. using Playwright). It is sometimes beneficial to bypass the frontend and target underlying systems (databases, Kafka etc.) that would only ever be used indirectly in production.
When load testing an AI service, you can send traffic to the LLM, or, in the case of agentic AI, to the tools/services that the LLM would call.
Calling your tools directly has multiple benefits:
- More predictable behavior and less variation in response times
- Lower cost (no need to pay for the LLM)
- Focus on the things that don’t scale (assuming you can just pay your vendor for more LLM compute)
Of course, it also has the usual down sides of component testing
- Risk of missing changes in behavior of other components (e.g. if changes in your model changes the way it calls the tools)
Here’s a basic example using Anthropic’s Model Context Protocol (MCP).
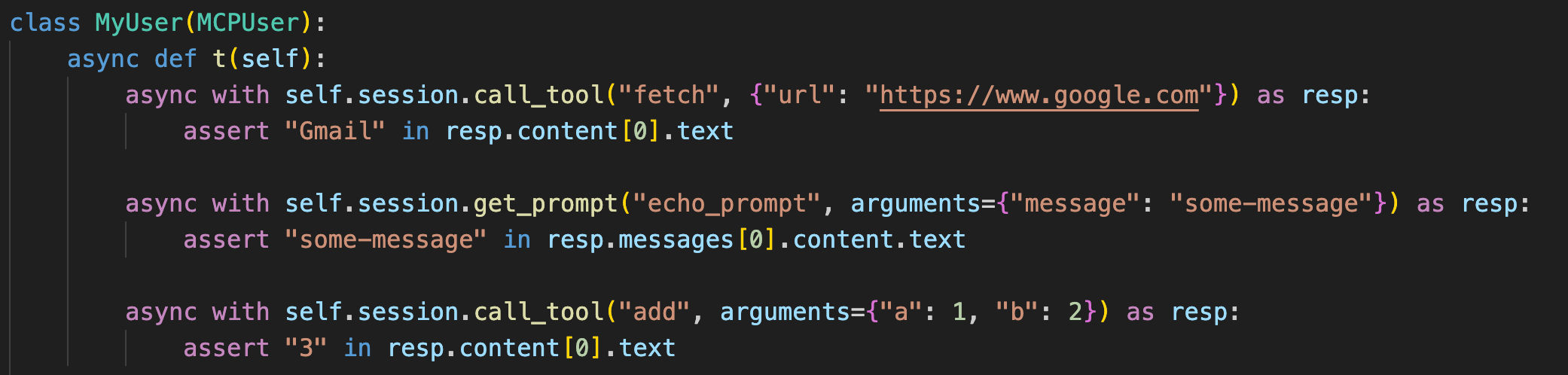
MCPUser is not yet released in Locust, but it’s getting there. Let us know if you are interested in a sneak peek!
Tooling
Rather than implementing load test scenarios on the protocol level, there is a lot of benefit to doing it using an SDK, especially if you are already familiar with it.
OpenAI API is rapidly becoming the standard, even for other LLMs and has a very nice SDK for Python. Here’s how to load test it using Locust (full example here):
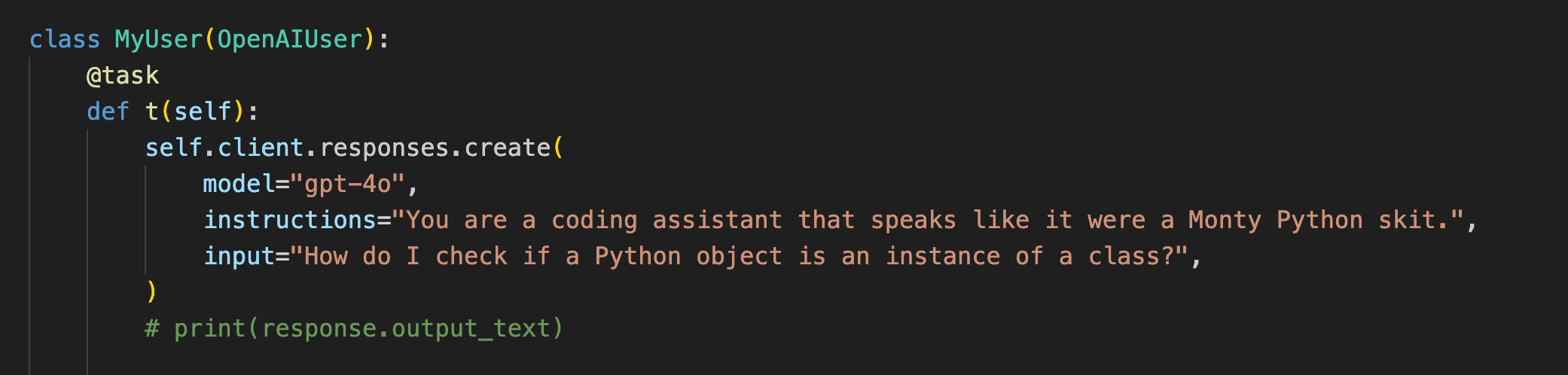
This support for OpenAI API was just introduced into Locust, let me know if you have any feedback!
Metrics
Some AI requests are like plain HTTP requests in that they have a single response time (typically time from request to last byte), but because responses are typically streamed it does not provide a complete picture.
Often, you’ll want to also measure:
- Number of Generated Tokens (per second)
- Time to First Token (TTFT)
- Inter-token Latency (ITL)
If you’re using a flexible load testing tool like Locust, you can write code to manually keep track of these metrics, or rely on Locust Cloud’s graphing capabilities (in this case tracking the number of generated tokens/s, in a graph that would ordinarily show bytes/s):

Tokens/s
What to test, and what not to test?

As always with load testing, the most important thing to test is anything that cannot be trivially scaled up. If you are hosting your own LLM, then that is definitely something you need to load test, but if someone is hosting it for you, it might make more sense to trust your provider’s promise of capacity, directing more focus to things like scale-out latency, or systems backing your LLM.
When testing scaling, there are additional metrics you’ll want to track, like instances available, proper distribution of load across servers etc. More about that in a future post…
Closing thoughts
To sum up: test what doesn’t scale, target tools/underlying services directly where it makes sense, and track the right metrics.
If all of this feels overwhelming, we want to help! Reach out to us here. We’re particularly interested in helping people just getting started with their AI load testing journey.
Lars Holmberg • 2025-04-24
Back to all posts